Working with clean, well structured binary classification problems is one thing, but being able to manipulate any image data and fine tune the model to achieve the most in the least time is another cake.
In this section we will learn some basics of image data sets structures and how to fine tune the model to improve generalization and performance. In doing so we reach winning level performance in a real life problem of wildlife detection in the jungle.
Using pytorch and fastai on a real data set
The internet is full of tutorials with very curated data sets, here I am going to use a real data set from one site called drivendata, which contain many great competititions to use ML/DL for social and environmental problems.
https://www.drivendata.org/competitions/87/competition-image-classification-wildlife-conservation/page/409/
The goal is here to detect species that are moving, at night... so this is quite challenging but also fun as this is a real problem. I will go through the learnings of the fastai lesson in the context of submiting a solution for a classification of 8 different specifies of animals in the jungle: 'antelope_duiker','bird', 'blank','civet_genet', 'hog', 'leopard', 'monkey_prosimian', 'rodent'. Note that as in real life some images will not have animals and hence will be blank. Note though that there is some curation as the distribution of animals and classes is quite uniform, something you would not encounter in reality.
monkey_prosimian 0.151140
antelope_duiker 0.150049
civet_genet 0.146955
leopard 0.136705
blank 0.134219
rodent 0.122089
bird 0.099527
hog 0.059316
dtype: float64
How is the data created?
In order to leverage the functionalities of fastai and pytorch, we need to be able to understand how the data is structure and where to find the labels. In this particular case, we have three key files for training and validation:
- The train_features folder contain around 16K images of animals in outdoor space, at day and at night with lots of difference in quality and also the location of our target object (Animal class) changes. Find below two examples one a mouse is found at night (bottom right) and second a monkey with his/her child is found in the middle:
This information is key to create the labels and process the images for our DataLoader and later to use fastai learners.
Having a simple pytorch benchmark
- Processing time: 5 min x epoch ~ 25 min
- Cross entropy loss after 5 epochs training set ~ 1.2 Cross Entropy loss - baseline submission is 1.8, an initial value is 2, so 40% reduction from random and 3 times the reduction of baseline.
- Accuracy on validation set : 43% over 8 classes (3 times better than 12% random guess) - strong results on civet, leopart and rodents, while in the others we are less than 50% right.
Instead of playing further with pytorch, we will leverage fastai functionalities to:
- create a data block
- leverage fastai API for resizing, augmentations, transfer learning
- leverage fastai API to fine tune for learning rate
- compare performance (cross entropy, accuracy, processing time) on pure pytorch set up versus fastai with a resnet34 and 50
Creating Data Loaders and Image Blocks with Fastai
Note that most of the image data is structure in one of these two ways:
- Images organized in files where each file contain a class
- Images in one file and csv with metadata and mapping each image path with a class
In the data set for that hackathon, the original file was like the latter, and I put some code to change it to look like something very much like the PETS data set:
My output -> Path('/content/drive/MyDrive/wildlife/train_features/images/ monkey_prosimian_9780.jpg'A sample from the pets data set: /home/jhoward/.fastai/data/oxford-iiit-pet/images/american_pit_bull_terrier_31.jpg
Note that after the last underscore there is always a number, this is key when we create the data loader that automatically get the label (everything before the last underscore and number).
The following code creates a data block and a dataloader object which is our building block to train models:
wild = DataBlock(blocks = (ImageBlock, CategoryBlock),
get_items=get_image_files,
splitter=RandomSplitter(seed=42),
get_y=using_attr(RegexLabeller(r'(.+)_\d+.jpg$'), 'name'),
item_tfms=Resize(460),
batch_tfms=aug_transforms(size=224, min_scale=0.75))
dls = wild.dataloaders(path)
There are some key elements to understand what this chunk of code does:
- splitter sepates the data into training and validation and fixes the seed - by default the split is 80/20 for training and validation.
- get items define how we load the files - we leverage the get image files from fastai, but one can created custumized loading functions. Here is a great tutorial how the get image files works (https://kurianbenoy.com/2021-08-07-get_image_files/)
- get_y leverages regular expressions to find the label as everying before the last underscore and number, ending by .jpg.
- item_tfms and batch ftms allows you to decided on which standard size to perform your augmentations at batch. Note the following
- First we resize all the images to 460
- Later we crop full width or size of 224x224
- The we applied augmentations on each batch (random crop and augment)
- The reason for that is the making images bigger first ensure there is no massive information loss or blank pixels when cropping or rotating images.
With this in place we can start training our first model and discuss how to improve it. Before training please use show_batch and summary on the data loader to debug the data block.
Training the first model
In the first model, we will use a common resnet34 architecture in order to leverage what has been learned while training a model on the ImageNet data set. We will ask our learner object to print the error rate as a metric, and the only additional required input is the data loader. After 14 min we get the following results.
learn = vision_learner(dls, resnet34, metrics=error_rate)
learn.fine_tune(2)
Would like to explain what fine_tune does to our learner object:
- first update the last layers based on our actual data set and classification problem, trying to minimize the cross entropy loss, leaving the other trained weighted from previous layers fixed/frozen.
- then, for two full passes of the data or epochs, we unfreeze all the weights to adjust for our data set.
First, note that fastai select the loss function for us given the multiclass nature of our problem. Second, there are good reasons to implement the training in this way:
- First we freeze pretrained weights as they should help already for the task as they have learned basic image features such as corners and shapes, but also different abstractions (cat, chair, tree..).
- After that step, we update not only the last layer for the classificatin but also previous layers. We will deep dive later on the learning rate of each layer, as this is key to understand the success of fastai.
One can already see that we have already beat the previous validation loss (with only two epochs) and training time from our baseline (even training on the full data set). Improving performance with more data is not surprising, but improving both validation loss and processing it is.
Before we jump into fine tunning, let's take a moment to fully understand cross entropy loss and why it is use for this type of problems.
Why Cross Entropy loss is used for multiclass problems?
When we are classifying multiple classes, we are providing a number between 0 and 1 to each class, summing all of them one. The activations required to provide such values are sigmoid, and to ensure that the sum up to one we applied the softmax function. The softmax function uses an exponential function to each logistic activation and sum the exponential of each prediction to ensure they sum up 1.
Exponentiation is not only used for normalization, but to push differences in probabilities between cases further away. As we want to pick one class, we want to softmax to gives us a clear winner.
The softmax calculation of each class does not give us the cross entropy yet. The next step consists con calculating the log loss. We are interested on the loss of the correct class, so we calculated the loss as the difference between the predicted probability and the actual value. Instead of taking the mean directly of the losses, we calculate the mean of the logarithm of the losses. The reason for that is to ensure we have a well behaved loss function that does not fluctuate extremely for changes on some loss value. Put it differently, we linearize the gradient of the loss, ensuring the are not sudden jumps based on the loss of certain observations. This is important computationally as we do not have erratic updates on the weights, but also for performance, as we are transition to lower loss values smoothly.
How can I improve my model?
In the previous post, a key message is that
data cleansing can heavily improve your model, specially when you are pulling data from uncurated sources (
Brand Classifier with FastAI) . Here
the focus will be in how to decide the learning rate, the number of epochs and the architecture.
Before I jumped into the rate finder, the confusion matrix on the validation set show that, despite some animals are not classifed as accurate than others (birds and rodents are harder than leopards or civets genets), this is not surprising as they differ in size massively, an they can be easily get confused with movement or poor light. Nothing suggest something is really wrong, as with most classes we are getting 70% or more accuracy. Bigger animals are classify easily, as expected.
The following snippets give you the confusion matrix and the most confused pairs:
interp = ClassificationInterpretation.from_learner(learn)
interp.plot_confusion_matrix(figsize=(12,12), dpi=60)
interp.most_confused(min_val=5)
Finding the Learning Rate
The learning rate belong to the group of parameters called hyperparameters. They are not learn during the training process, but rather have to be defined beforehand. What many practitioners have done so far is :
- Use typically know good values : 0.001
- Apply a grid on multiple values: [0.005,0.001,0.0001]]
Both options are suboptimal, and could lead to overshooting or too slow learning. Reducing the number of epochs or passes on the full data set is good to avoid overfitting, and therefore finding a good learning rate value for our dataset is good to save computing but also to achieve great performance.
The Learn rate finder implemented in Fastai is surprisingly simple yet work very well. The idea is to apply progressively higher learning rates on batches of data and see when there is the greatest change in loss reduction, not to close to a subsequent overshoot but also far from flat areas.
This allow us to find a much better learning rate that random guess or the expensive usage of a grid. The output looks like the following:
We can see that using a learning rate of 0.003 gives us the steppest reduction in the loss for a given batch. Let's try to fine tune our model again with such a rate:
With the same numbers of epochs we achieve a validation loss of 0.79, which is less than the one with the learning rate we place before (0.001), note that if we would set a order of magnitude less, our loss would have been around 8% higher, and probably took much longer to get similar result.
Unfreezing Layers and Doing Transfer learning
As we have said before, we normally start by freezing the pretrained layers and only update the head layer, or the one which will give the input to the softmax function. That gives us a loss of ~1.4, better than the 1.8 as baseline we can probably benefit from unfreezing all the weights and adjust them for the task at hand, as our jungle camera shooting is quite different than the nicely curated images from ImageNet. As one can see from the following article Visualize Neural Nets , the first layers learn basic details such as shapes, corners... while the last ones leaner abstract concepts. Because of that, we may one to train our model with different amount of learning rates for the early layers (rather low) and higher to the middle and finish with low learning rates again. This is called discriminative learning rate, and this is applied when we call fit_one_cycle. We will do this for more epochs to see to which extend the model improve.

We manage to push down the validation loss from 1.4 to 0.7, and we are classifying more than 75% of the wild animals correctly. Note that we need to specify the slice of learning rate to be applied after unfreezing all layers. The following plot shows nicely how the loss goes down for both the training and validation set, without any signs of overfitting.
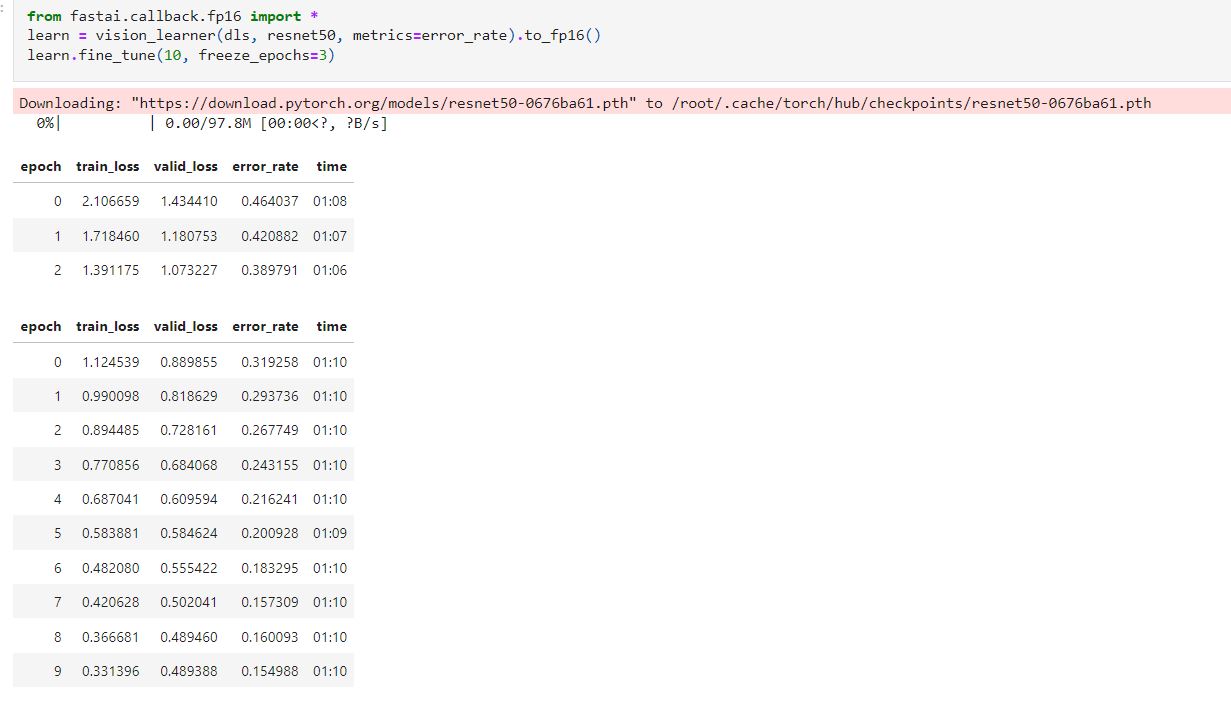
To finish up we will try a deeper neural net, resnet50, with 3 frozen epochs and 10 epochs in total.
Trying Deeper Neural Networks
One cannot a priory say which resnet will perform better. What it is clear is a deeper neural nets take longer to train and are more prone to overfitting. So we should start by smaller ones such as resnet 18, 34. Given the complexity of the image set of the challenge, and the fact that there is not evidence from overfitting, its seems like a worth intent to train resnet50, with a little trick to speed up training (changing the precision of the numbers stored).
Boom! we got
85% of accuracy and 0.48 of validation loss. One can see in the notebook that the training and validation loss only look slightly worse, so we will export that model and use it for the competition.
Notebook with the full code)
At the time of this writing this submission is the winner, altought I am suspicies abut the log loss reported (is very high compared to the validation set, submitting same file has given me fluctuating values). Visually looking at the test images there is not sign of them being harder.
Concluding remarks
FastAI is more than a highlevel library to learn deep learning. It is a powerful library to achieve state of the art results leveraging transfer learning and simple yet practical implementation tricks to make training fast and effective. I went the extra mile and go for a very hard problem, with pretty low quality images to classify animals moving, in the jungle and at different times of the day and we achieve 85% accuracy on the validation set.
The secret is not in computing or massive data sets, as I used 1GPU and 10000 images, but rather in leveraging transfern learning, learn rate finder, learn rate discrimation, good augmentation policies and a very efficient pytorch implementation. In the next post we will explore other computer vision problems.











Comments
Post a Comment